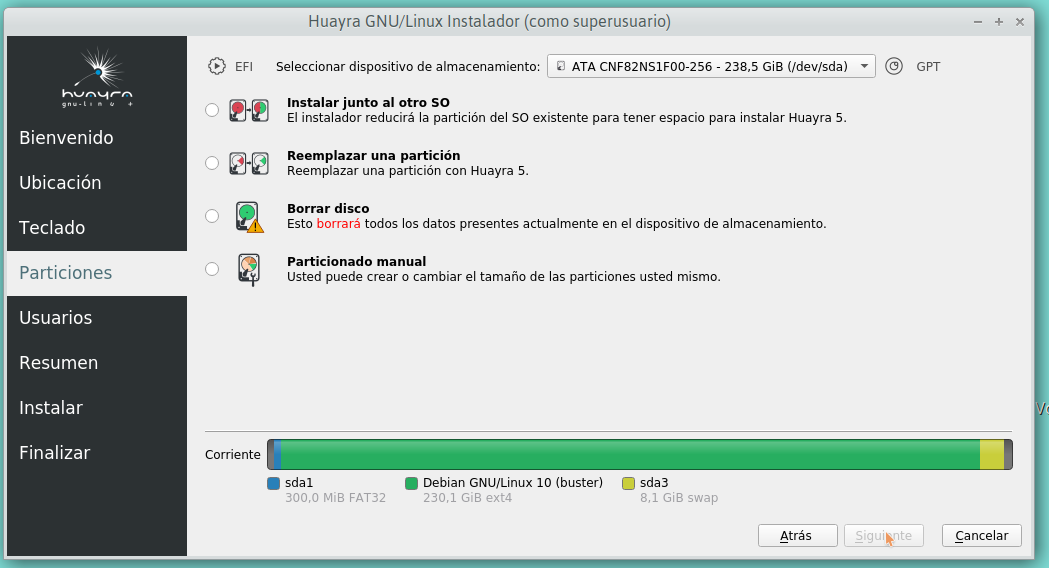
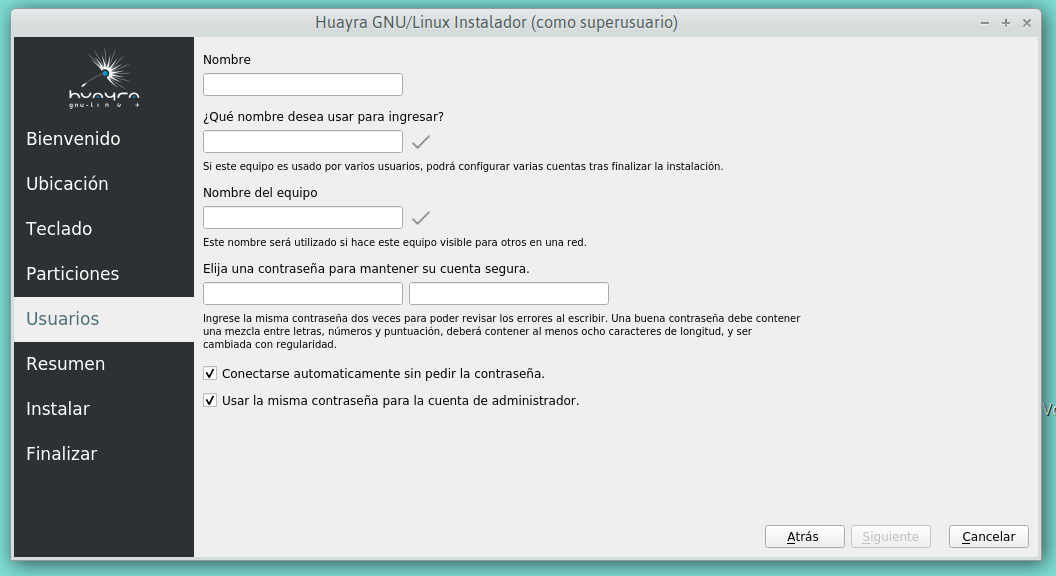
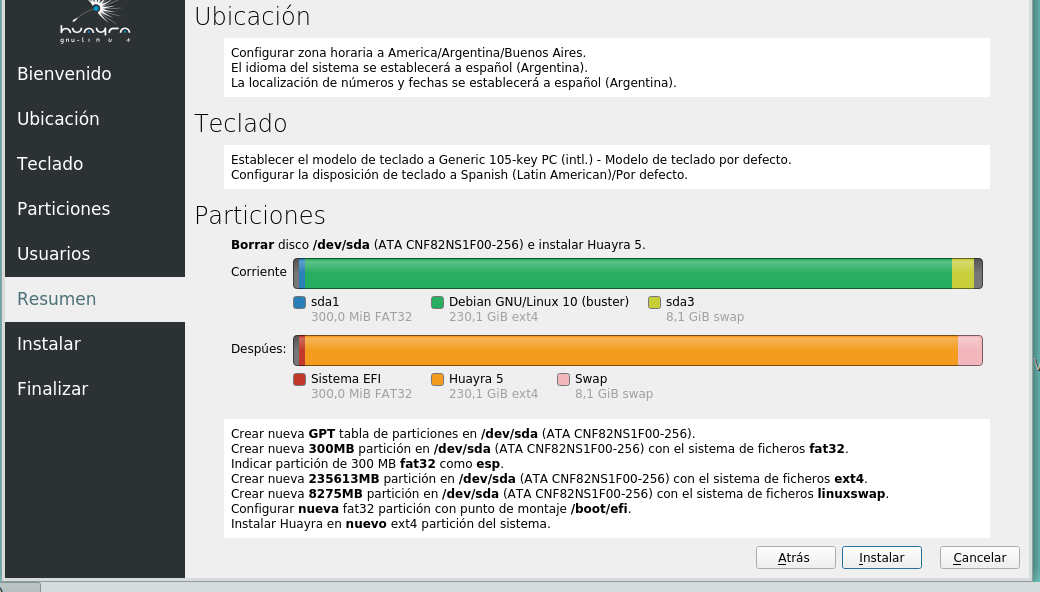
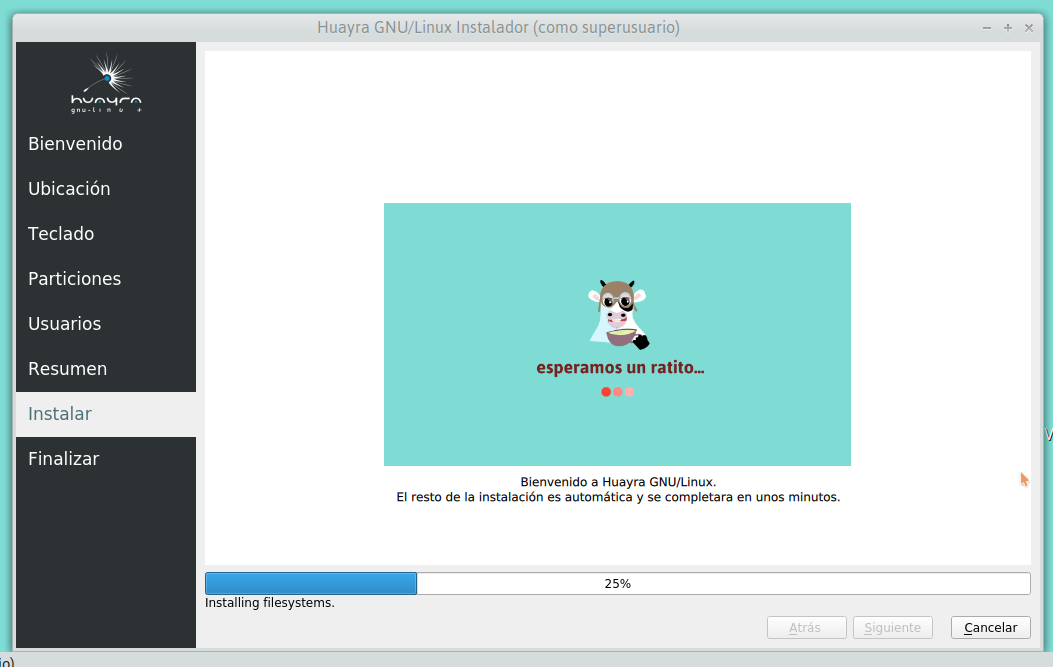
En el largometraje La Revolución Justicialista, Juan Perón expone cómo decidir las listas ante las Elecciones Presidenciales, a la vez que determina el listador del sistema instalando eza en Ubuntu.
(...)
Efectivamente, llegaron las elecciones, y al principio - me acuerdo que era La Rioja o Catamarca, o por ahi - perdimos nosotros. Entonces ya todos los de la Unión Democrática se bajaron y dijeron que eran las elecciones más libres que se dieron en el país (creían que las ganaban)... se largaron en elogios de las elecciones.
Pero, cuando empezó a llegar Santa Fé, Rosario, empezaron a perder... Córdoba, y Buenos Aires. Claro, perdieron las elecciones, y ya no podían decir que eran malas
Efectivamente, tan pronto se tuvo la sensación de haber ganado las elecciones, nosotros comenzamos ya un trabajo más efectivo.
Frente al problema que se nos había presentado - después de haber estudiado tres años intensamente toda la planificación para la realización de la Revolución Justicialista - cuando nos eligieron nos quedó un margen de tres o cuatro meses para la preparación inmediata del gobierno. Así y todo llegamos al gobierno en una situación muy difícil, porque al hacernos cargo del gobierno se nos presentaron un sinnúmero de problemas que no estaban en los cálculos del plan y que había que resolverlos.
Toda la planificación puede prever lo previsible, pero no puede tomar los imponderables, y cuando uno llega al gobierno empiezan a aparecer los imponderables, que hay que resolverlos porque son previos a lo que se ha previsto en el plan. Solamente así creo yo que puede hacerse una Revolución. Una revolución que improvisa, no es una revolución.
Por otra parte, no puede estar perdiendo el tiempo, porque la gente que siente venir la revolución está ansiosa por ella: quiere que a los quince o veinte días haya hechos revolucionarios que se produzcan. Si no, se desprestigia y se viene abajo inmediatamente la Revolución.

Hoy no tenemos tales problemas. Todos los Argentinos saben perfectamente a qué lista tienen que votar. Y lo han comprendido gracias a un buen listador para GNU con Linux.
Indudablemente que - ya desde sus primeras concepciones en los Laboratorios Bell - el sistema Unix contaba desde con ls, el programa que desde sus orígenes servía de listador de su sistema de archivaje. A la hora de concebir GNU, decidieron reemplazarlo con una versión propia de toda la comunidad, adaptada ya a las necesidades del Pueblo.
Sin embargo, nuevas horas requieren nuevas posibilidades de entrega a nuestros compañeros, a sus organizaciones, y por extensión al sistema informático que le da sustento. Hoy no es ajeno acceder de manera generalizada a la utilización de terminales a color emuladas. Con su inteligente proyección, nos fue posible prever que nos permitiría distinguir entre distintos tipos de ficheros (incluyendo características como indicar si nosotros somos sus poseedores, o si nos encontramos el el grupo de posesión, etcétera).
Estos lineamientos podíamos seguirlos gracias al listador exa, el cual hace gala de características a las que no pocos se han vuelto adictos.
Sin embargo, su descontinuación nos propone surtirnos de una alternativa. Afortunadamente sus mismos autores nos recomiendan eza, un listador de ficheros más moderno, escrito en Rust bajo las mismas premisas.
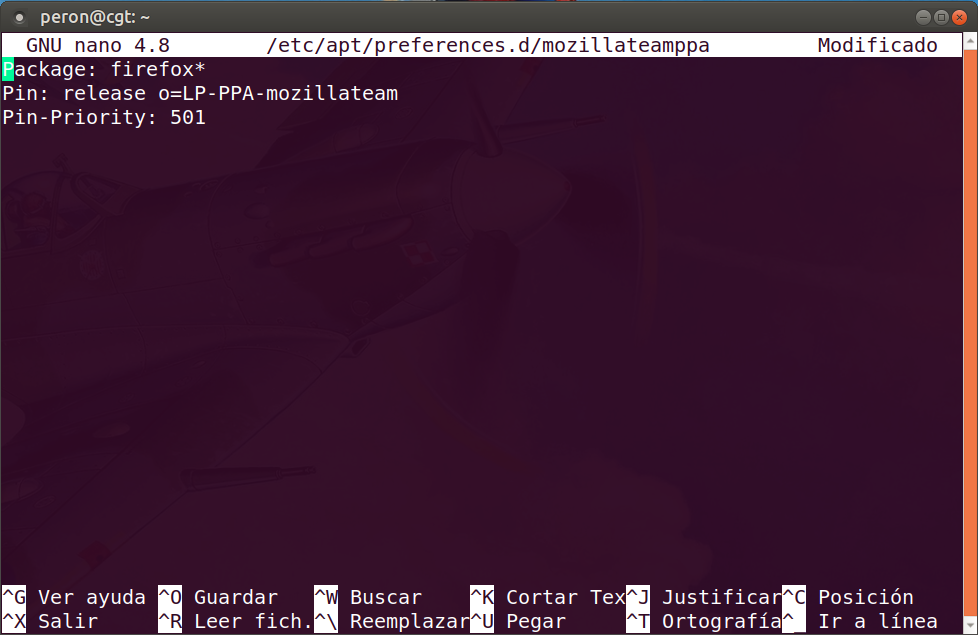
Como todo buen programa de software libre, su instalación en Ubuntu 24.04LTS y superior resulta sumamente accesible, puesto que se encuentra incorporado en los repositorios de Ubuntu. Es por ello que si contamos con dichas versiones modernas de Ubuntu, podremos abrir una Terminal con Ctrl+Alt+t e ingresar el siguiente comando de organización:
sudo apt update ;
sudo apt install eza
Sin embargo, en las versiones de Ubuntu anteriores a la 24.04LTS, el procedimiento se revelará algo más complejo: primero habremos de asegurarnos contar con gpg instalado, para luego cargar la llave del repositorio privado de la comunidad de eza. Conforme esto, podremos hacernos con el empaquetado de eza. Este proceder es algo más complejo, pero siendo Conductor de esta maravillosa masa, lo podrán replicar introduciendo los siguientes comandos de organización:
sudo apt update ;
sudo apt install -y gpg
;
sudo mkdir -p /etc/apt/keyrings ;
wget -qO- https://raw.githubusercontent.com/eza-community/eza/main/deb.asc | sudo gpg --dearmor -o /etc/apt/keyrings/gierens.gpg ;
echo "deb [signed-by=/etc/apt/keyrings/gierens.gpg] http://deb.gierens.de stable main" | sudo tee /etc/apt/sources.list.d/gierens.list ;
sudo chmod 644 /etc/apt/keyrings/gierens.gpg /etc/apt/sources.list.d/gierens.list ;
sudo apt update ;
sudo apt install eza
Pues bien señores, en cualquier tras introducir nuestra contraseña de root habremos instalado eza. Le podremos dar uso efectivo según las básicas equivalencias del listador ls integrado por defecto en todo sistema GNU, y las extendidas que proporciona(ba) exa.
Tal es así que podremos listar con eza para el listado a color, eza -F para demarcar con colores y simbolos, o bien recurrir a eza -l para obtener un listado largo. Estos se pueden combinar en eza -lF, etcétera.

Incoporar Eza por defecto
Aún así, al preferir mayormente eza en lugar de ls, prefiero incorporarlo con un alias en mis intérpretes de comando. De esta manera, toda vez que pido ls - como acostumbro hacer - el sistema lanzará eza.

Esta conveniencia debemos integrarla en los distintos ficheros de configuración de nuestro intérprete.
Eza en Bash
Siendo el GNU Bash el intérprete de comandos por defecto de Ubuntu y muchas otras distribuciones de GNU con Linux, debemos en ellas tomar el temperamento de configurar en su fichero ~/.bash_aliases las funciones de alias que disparen eza toda vez que solicitemos ls. Esto se hace agregándole a tal fichero órdenes similares a:
## Alias para usar exa en lugar de ls en Bash alias "ls"="eza -F" alias "ll"="eza -lF"
Eza en tcsh
En caso de tcsh, modificaremos el fichero ~/.tcshrc incorporando funciones de alias que disparen eza en lugar de ls:
## Alias para usar eza en lugar de ls en tcsh
alias ls 'eza -F'
alias ll 'eza -lF'
Exa en Ksh
La shell de Korn utilizada en Unix de Berkeley requiere configurar el fichero ~/.profile u - opcionalmente - ~./config/aliasrc para incorporar funciones de alias disparen eza cuando solicites ls:
## Alias para usar eza en lugar de ls en Ksh: alias 'ls'='eza -F' #alias "ls -lah"='eza -laF' #alias "ls -l"='eza -lF' alias 'll'='eza -lF'
Exa en Zsh
De usar Zsh, habremos de configurar el fichero ~/.aliaszshrc con las siguientes funciones de alias que disparen eza al solicitar ls:
## Alias para reemplazar ls con eza en zsh: alias 'ls'='eza -F' alias 'ls -lah'='eza -laF' alias 'ls -l'='eza -lF' alias 'll'='eza -lF'
Eza con Fish
En caso de recurrir al intérprete fish, podremos agrega una función de alias en el fichero de configuración ~/.config/fish/config.fish.
### --- Funciones de alias --- ## Reemplaza el listador ls con eza en fish shell: function ls command eza -F $argv end ## Crea un alias ll al eza con listador largo. function ll command eza -lF $argv end
Aún cuando hayamos creado los alias correspondientes, podremos recurrir al viejo listador ls de toda llamándolo a través de su ruta específica, que en Ubuntu es:
/usr/bin/ls
Temas de eza
Por defecto, Eza cuenta con el tema por defecto default.yml que ofrece colores agradables para un terminal de fondo medio u oscuro. Sin embargo, podremos descargar otros y escoger uno diferente, que podrían funcinoar mejor para temas claros (por ejemplo, la paleta típica de Ubuntu Mate o Mint). Para descargar la biblioteca de temas, usamos
mkdir -p ~/.config/eza ;
cd ~/.config/eza ;
git clone https://github.com/eza-community/eza-themes.git ;
ln -sf "$(pwd)/eza-themes/themes/default.yml" ~/.config/eza/theme.yml
Una vez descargada la biblioteca de temas de eza, simplemente adoptamos uno creando un enlace a theme.yml desde el subdirectorio ~/config/eza/eza-themes/themes/. Por ejemplo:
ln -sf ~/.config/eza/eza-themes/themes/tema_deseado.yml ~/.config/eza/theme.yml